Redis 系列文章(一)
Redis数据结构底层实现
Redis作为一个c语言实现的高效率内存数据库,底层使用了很多高效的数据结构,平常我们会使用到它那些结构应用到业务场景呢,下面给些回答:
最普通kv set key value 字符串对象,底层编码实现 sds int embwar raw,Redis设计和实现上比较好的一点是 数据类型的支持和底层编码分开,redis支持的数据类型有 string hash set zset list等,某个数据类型都有多种编码方式,比如 string 就有 int embstr raw 三种方式 hash有ziplist和hashtable等方式,这样的设计使得数据类型和底层编码分开,后续拓展编码方式很容易,具体如下
List 数据类型底层数据结构由「双向链表」或「压缩表列表」实现;
Hash 数据类型底层数据结构由「压缩列表」或「哈希表」实现;
Set 数据类型底层数据结构由「哈希表」或「整数集合」实现;
Zset 数据类型底层数据结构由「压缩列表」或「跳表」实现;
string 在redis中的机构 string存储最大512M 是二进制安全的 也就是说可以存储图片等二进制数据
String 底层数据结构
Redis 5.0 的 SDS(simple dynamic string) 的数据结构
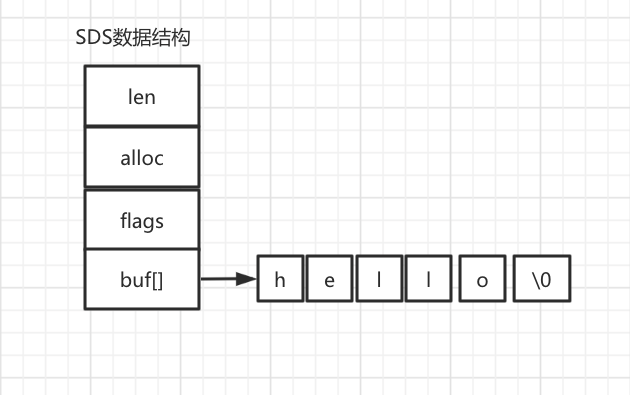
具体详细介绍如下:
len,SDS 所保存的字符串长度。这样获取字符串长度的时候,只需要返回这个变量值就行,时间复杂度只需要 O(1)。c语言原生char类型为O(n)
lloc,分配给字符数组的空间长度。这样在修改字符串的时候,可以通过
alloc - len计算 出剩余的空间大小,然后用来判断空间是否满足修改需求,如果不满足的话,就会自动将 SDS 的空间扩展至执行修改所需的大小,然后才执行实际的修改操作,所以使用 SDS 既不需要手动修改 SDS 的空间大小,也不会出现前面所说的缓冲区益处的问题。flags,SDS 类型,用来表示不同类型的 SDS。一共设计了 5 种类型,分别是 sdshdr5(貌似已废弃,待确认)、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64,后面在说明区别之处。
buf[],字节数组,用来保存实际数据。不需要用 “\0” 字符来标识字符串结尾了,而是直接将其作为二进制数据处理,可以用来保存图片等二进制数据。它即可以保存文本数据,也可以保存二进制数据,所以叫字节数组会更好点。
总的来说,Redis 的 SDS 结构在原本字符数组之上,增加了三个元数据:len、alloc、flags,用来解决 C 语言字符串的缺陷。
节省内存空间
SDS 结构中有个 flags 成员变量,表示的是 SDS 类型。
Redos 一共设计了 5 种类型,分别是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64。
这 5 种类型的主要区别就在于,它们数据结构中的 len 和 alloc 成员变量的数据类型不同,
比如sdshdr16 和 sdshdr32
1
2
3
4
5
6
7
8
9
10
11
12
13
14struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len;
uint16_t alloc;
unsigned char flags;
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len;
uint32_t alloc;
unsigned char flags;
char buf[];
};- sdshdr16 类型的 len 和 alloc 的数据类型都是 uint16_t,表示字符数组长度和分配空间大小不能超过 2 的 16 次方。
- sdshdr32 则都是 uint32_t,表示表示字符数组长度和分配空间大小不能超过 2 的 32 次方。
- 之所以 SDS 设计不同类型的结构体,是为了能灵活保存不同大小的字符串,从而有效节省内存空间。比如,在保存小字符串时,结构头占用空间也比较少。
- 除了设计不同类型的结构体,Redis 在编程上还使用了专门的编译优化来节省内存空间,即在 struct 声明了
__attribute__ ((packed)),它的作用是:告诉编译器取消结构在编译过程中的优化对齐,按照实际占用字节数进行对齐。
压缩列表
压缩列表是 Redis 为了节约内存而开发的,它是由连续内存块组成的顺序型数据结构,有点类似于数组。
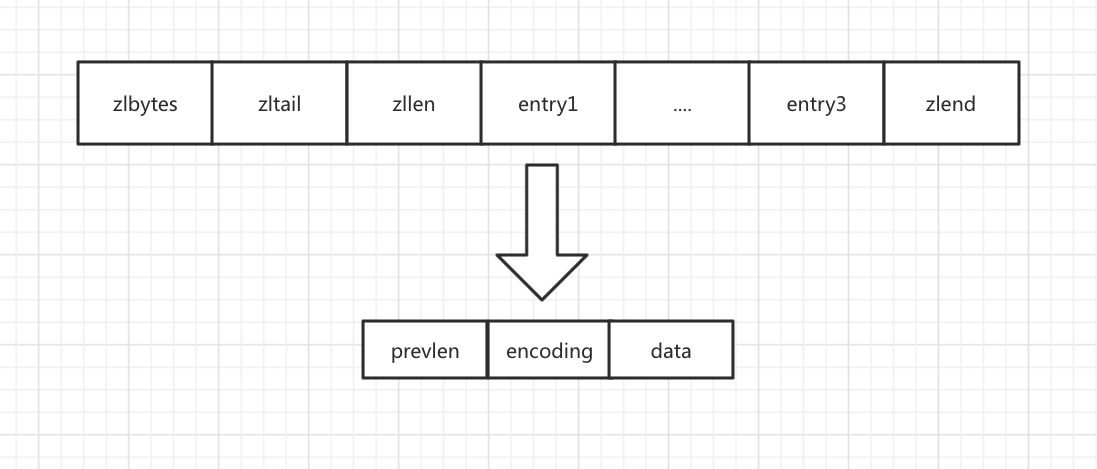
压缩列表在表头有三个字段:
zlbytes,记录整个压缩列表占用对内存字节数;
zltail,记录压缩列表「尾部」节点距离起始地址由多少字节,也就是列表尾的偏移量;
zllen,记录压缩列表包含的节点数量;
zlend,标记压缩列表的结束点,特殊值 OxFF(十进制255)。
在压缩列表中,如果我们要查找定位第一个元素和最后一个元素,可以通过表头三个字段的长度直接定位,复杂度是 O(1)。而查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N) 了。
压缩列表节点包含三部分内容:
- prevlen,记录了前一个节点的长度;
- encoding,记录了当前节点实际数据的类型以及长度;
- data,记录了当前节点的实际数据;
连锁更新
压缩列表除了查找复杂度高的问题,压缩列表在插入元素时,如果内存空间不够了,压缩列表还需要重新分配一块连续的内存空间,而这可能会引发连锁更新的问题。
压缩列表里的每个节点中的 prevlen 属性都记录了「前一个节点的长度」,而且 prevlen 属性的空间大小跟前一个节点长度值有关,比如:
- 如果前一个节点的长度小于 254 字节,那么 prevlen 属性需要用 1 字节的空间来保存这个长度值;
- 如果前一个节点的长度大于等于 254 字节,那么 prevlen 属性需要用 5 字节的空间来保存这个长度值;
所以一般ziplist保存元素不会很多
Redis 实际项目中应用场景
(1)排行榜
ziplist zrank zreverange
1 | zadd ranklist 300 apple 500 banana //添加排行榜内容 |
(2)月打卡签到
bitmap 实现底层
1 | # 2021年3月1号签到 |
(3)地理位置 geo
1 | # geoadd location_set longitude latitude name |
(4) 月pv uv统计
1 | # hyperlog 月pv uv统计 |
Linux环境上的redis优化
1 最大打开文件句柄数
1 | ulimit -Sn {max-open-files} |
2 Tcp backlog
1 | cat /proc/net/sys/core/somaxconn |
vm.overcommit_memory建议为1
Linux > 3.5 vm.swappiness建议为1 否则建议为0
Transparent Huge Pages (THP)建议关闭 但注意linux发行版本改变了THP位置
可以为Redis设置 oom_adj 减少redis被OOM killer概率 但不能过渡依赖
建议对Redis所在节点 使用NTP服务,同步时钟
设置合理ulimit保证网络连接正常
设置合理的tcp-backlog参数
Redis 安全
1 设置密码 requirepass 设置密码长度为64个字节以上
2.伪装危险命令
引入renamecommand 比如
1 | rename-command flushall 12312312fascsfsfsfsfs |
3.防火墙
4.bind
bind指定了 redis 绑定那块网卡可以进行访问
5bigkeys 阻塞问题
redis-cli –bigkeys 可以查找占比比较大的key
另外可以通过 debug object key 查看一个key是否是bigkey 可以查看这个命令返回的 serializedlength属性 返回序列号字节数
其他待深入学习
Redis运维平台(CacheCloud)
github redis-migarate-tool 唯品会开源迁移工具
Redis bitmap 实现布隆过滤器 https://github.com/erikdubbelboer/redis-lua-scaling-bloom-filter
redis-faina
paketbeat ELK 抓取日志收集器
RedisLive工具
参考资料
《Redis设计和实现》
《Redis开发和运维》